Publications, news articles and other documents in the government section can now be tagged directly to relevant topics, instead of the topic being inferred automatically via policies. This is a significant change, so publishers in government organisations may want to read this post closely.
How it worked before
Previously, documents in the government section could only be tagged to policies, from which the publishing software automatically inferred the relevant topic.
We designed it that way deliberately, to encourage publishers to think about how each document they are publishing relates to the government's policies, so that:
- publishers are encouraged to avoid publishing things that are not relevant to what the currently elected government is doing
- publishers can identify gaps in the list of policies (ie, that a new policy needs to be created)
- end users can browse, subscribe and be alerted to all updates at a policy-level via the "latest"activity tab on each policy
- we can infer whether a document is relevant to local government and include it in the "only include results relevant to local gov" versions of email alerts
Recognising that it would still occasionally be necessary to publish content which does not relate to a policy, we left the "related policies" field as optional. Publishers are not forced to tag documents to a policy in order to publish them; but content published without being tagged to a policy will not show up on the relevant topic page, in the email alerts or atom feed for that topic, in local gov email alerts, and will not be findable by users when they apply topic filters to the announcements or publications pages.
Why we've changed it
The need to publish content which does not relate to policies, but which nevertheless relates to the higher level things that government does (represented by the topics), is more common than we realised.
Examples include:
- routine statistical releases about areas of government responsibility which don't directly relate to a policy
- responses to Freedom of Information requests about general issues or the policies of previous government administrations
- forms and guidance about things government is responsible for but not actively trying to change
Consequently, too much useful content was being omitted for users who choose to browse, subscribe or filter by topic.
How it works now
As of the release on 12 August, publishers can now associate the following document types to topics directly, either instead of or in addition to policies:
- news articles
- world location news articles
- speeches
- fatality notices
- publications
- consultations
- statistical data sets
The user interface looks like this:
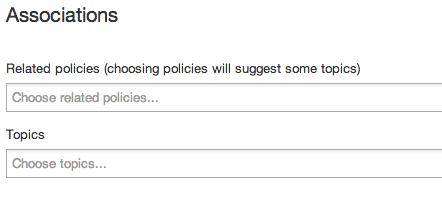
On selecting a policy, the inferred topics are automatically filled:
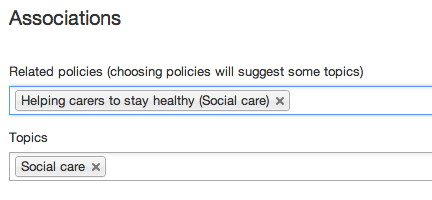
You can then add or remove topics for fine-grained control over the inferred topic associations:
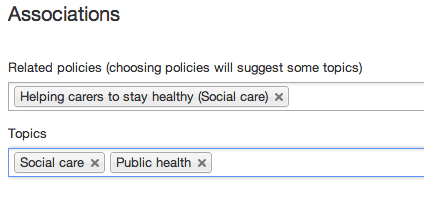
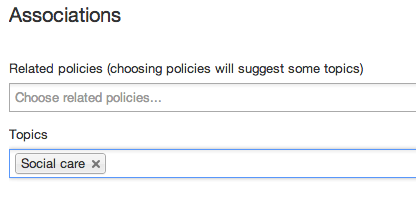
Or if you can't find a relevant policy, you can now choose one or more topics instead.
The importance of tagging to policies
It's vitally important that publishers continue to tag to relevant policies first and foremost, for all the reasons set out above.
Chief amongst them is this: end users should be able to rely on the "latest" list on a policy (and the resulting feeds and email alerts) as providing a complete list of all related updates.
To mandate or not to mandate?
We want to make it mandatory for publishers to pick either a policy or a topic. It's highly desirable that all documents should be findable from at least one of the topic options when filtering the announcements and publications lists.
However, the last thing we want is for publishers to have to tag things to irrelevant topics just to work around software restrictions. So before we make it mandatory, we want to gather more data about the kinds of document you may be publishing which do not relate even to a topic. If you encounter that kind of thing, please let us know via the comments on this post, or via the support form.
Cleaning up the data
Partly as a consequence of the way it worked before, but mostly as a consequence of the speed of transitioning sites into GOV.UK, there are currently 32, 000 published documents which are not tagged to any topics - that's around half of the published content.
We are doing some analysis of this content to automagically infer topics for these 32k documents based on the other available data (like their membership to document series, the text in their titles, and their sub-types). Having done so, we will need editors in departments to help fill the gaps and check our work, so we can then run a data migration to retrospectively tag these items to topics.
11 comments
Comment by Liz M posted on
Fantastic - this makes our lives much easier! Thank you.
Comment by Sheurie Warner posted on
We were told at the GDS Inside Government style workshop @ Thu 10 Jan 10:30 - 14:30 that publications should no longer be tagged to policies. Therefore, this new feature of being able to just tag to a topic will be useful.
We will be able to request new topics if a suitable one does not already exist?
Comment by Graham Francis posted on
Yes - we're always keen to make sure our set of topics matches the work of government. If you think you're doing something that people wouldn't naturally associate with one of the existing topics, please do tell us about it.
Comment by Sam Markey posted on
Hey, so how do I go about requesting a new tag? I think there's a gap around content related to (public) service reform...
Comment by Neil Williams posted on
Sheurie - I don't think we have ever said that you shouldn't tag publications to policies. That sounds like a misunderstanding. For ALL announcements/publications/consultations you should try to associate it to relevant policies, and only fall back to tagging directly to topics if there isn't a relevant policy. Thanks!
Comment by Ella posted on
Hello
Will you be updating the CMS user guide to include this new tagging option? If not, could you add an 'editorial' (or similar) tag to relevant blog posts? This would be very useful for new editors joining our team.
Ta
Comment by Liz Hitchcock posted on
Yes the user guide will be updated!
Comment by Ellen Booker posted on
Hi Liz
Do you know when this will be?
Thanks
Comment by lizhitchcock posted on
It is in draft, but the current manual which is linked from the Publisher dashboard contains guidance on tagging in the page on document formats
Comment by Flor posted on
Hi! How will we be sure what topic to choose? Writing a related word will bring up the suggested topics for us to choose? Or will there be a general list of topics available which we'll be able to check to make sure we're tagging content correctly? Thanks!
Comment by Neil Williams posted on
Hi Flor, the list of topics is finite and short enough to make this relatively easy: http://www.gov.uk/government/topics