In November we launched our first trial of the GOV.UK account. Jen Allum, Head of GOV.UK, wrote about why the GOV.UK account is part of our strategy to support users’ needs and offer a more tailored experience. We also recently blogged about how we designed the accounts trial and the user research behind our work.
We are using the trial on the Brexit transition checker to help us learn more about our users and how they interact with an account on GOV.UK. It was an obvious and important area where we believed we could give users a better experience by remembering their context and intention through an account. It is also helping us learn about the technical and operational aspects of building and managing an account. In building out an account we experienced the challenge of balancing our immediate need for a trial that we can quickly learn from, with our longer term vision of the technical architecture.
The central part of GOV.UK is a publishing platform and much of the content you can access on GOV.UK can be represented as static HTML. GOV.UK consists of a number of Ruby on Rails microservices that are split between publishing and rendering content. We simplify the scaling of GOV.UK by relying on caching at our Content Delivery Network (CDN) layer to serve most of our traffic.
We now want to offer a signed-in and more personalised journey that will eventually span multiple government services. This means we needed to challenge our current cache-heavy approach to create a more dynamic site.
This post outlines some of our thinking about the technical architecture, choice of authorisation and authentication platform, and hosting of the service as we evolve into this next phase of GOV.UK.
Phased architecture
Architecting a service-agnostic account that allows users appropriate visibility and control over their data is complex. We want to design an architecture which lets users stay signed in across multiple services so that users can experience a more personalised and joined-up journey.
Users should have control over how, when, and between which services their data is shared. At the same time service teams should not be able to see how individual users are interacting with other services; it should be very difficult for them to identify an individual user's journeys from any aggregated data.
A simple example of how this could be useful is the common action of filling in an address across many different government services. A well architected solution would allow users to fill their address in once and then, should the user choose to, share that data when they next need to fill in their address in a journey through a government service.
With ‘users first’ in mind, we also want to design something that meets these basic principles:
- users should have control over their data
- services should be blind to other services (service A doesn’t automatically need to know how a user has interacted with service B)
- aggregating journey data across services can provide useful insights, but we shouldn’t be able to identify individual user interactions across services
- data should be secure and there should be fraud protection and monitoring in place
Guided by these principles we drew an architecture diagram representing our desired end state for GOV.UK accounts. We worked with the Digital Identity team on the architecture diagram because we hope that in the future the GOV.UK Account will be linked to a cross-government digital identity service. Although we’re focused on building the account elements, we want to make sure this can work with a future digital identity solution, so we're working closely with our digital identity colleagues. Our initial version looked similar to this:
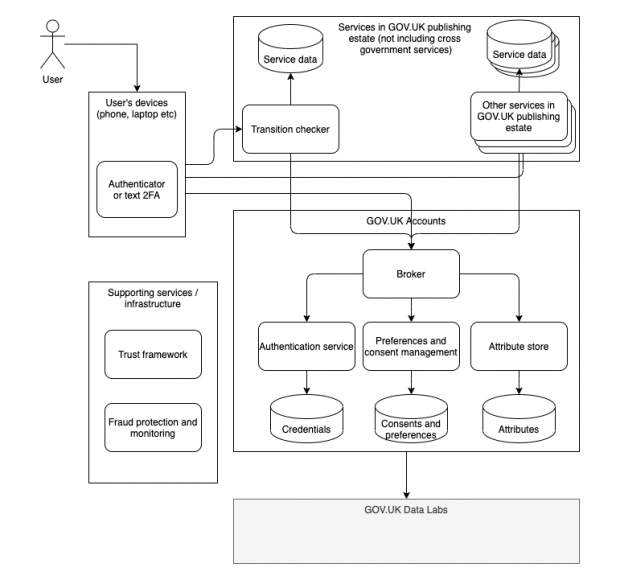
Architectural diagram of GOV.UK accounts
This architecture shows the interaction between a user, GOV.UK’s existing services, the proposed GOV.UK account services and GOV.UK Data Labs all underpinned by guarantees of trust, as well as fraud protection and monitoring.
The core GOV.UK account services include:
- an authentication - this handles user registration, two-factor authentication (2FA), subsequent sign-ins as well as things like password resets and confirmation emails
- an attribute store - a centralised location that holds some common data about a user that every GOV.UK service might need
- a broker - a service that all other services and the user interacts with and through, it blinds services from each other and makes sure services only access the personal data that users consent to sharing
- preferences and consent management service - this is responsible for allowing the user to control consent over how and when their data is shared as well as presenting the user with a security trail of when and where their data was used
Existing GOV.UK services interacting through the broker could then offer enhanced journeys to signed in users. To enable this, each service would most likely need some form of database or backing store to hold data unique to that service’s interaction with the user.
Important supportive aspects to this work are:
- a trust framework - this is responsible for ensuring and guaranteeing the trust of the various interacting services
- fraud protection and monitoring - a service that can proactively identify malicious or fraudulent behaviour and alert developers and security professionals
The GOV.UK account service also feeds anonymised data, if the user has consented, to the GOV.UK Data Labs team so we can analyse the user journeys and better understand how to streamline our services for users.
Building this entire architectural vision from the outset is a large task and because we wanted to launch a trial quickly, focused on a single service, we decided to introduce a phased architectural approach.
Creating a simplified architecture
We divided our architecture into smaller pieces so we could integrate the GOV.UK account with a single service. Without the constraint of multiple services interacting from the outset, we were also able to simplify what we needed to do to launch a trial.
For example, we didn’t need to blind services from each other because only one service was going to use the account. That meant we could defer building a broker until we actually need to onboard more services. Having only a single service using a GOV.UK account also meant we didn’t need to offer the user fine-grained control over how and where their data is going to be shared between services, again simplifying the number of components we needed to deliver.
We also made the decision to store the user’s answers to the transition checker questions in our attribute store so that we didn’t need to create a backing store for the transition checker itself.
Our simpler phase 1 architecture for our trial looks like this:
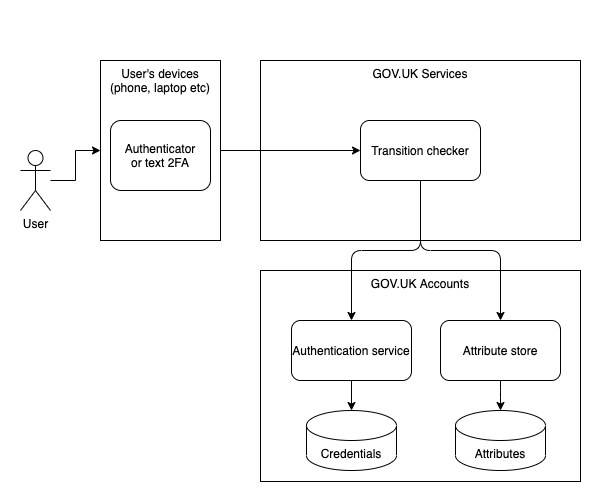
Understanding sign-in
The trial lets users sign in to an account so they can return to their Brexit Transition checker results page without having to fill in the same answers every time they visit.
Because we were expecting users to sign in to their account more than once, the first phase of our architecture needed some kind of authentication and authorisation.
Signing into services is common on the web and there are mature standards underlying authentication and authorisation. So we began our discovery by learning more about existing standards such as OAuth, OpenID Connect, WebID and how attribute exchanges work. We also spent time digesting the existing good practice guides on identity-proofing and authentication.
Then we looked at various existing open source and commercial authorisation and authentication solutions. We considered, among other solutions:
- reusing our publishing applications’ single sign-on
- using self-hosted open source solutions such as Keycloak or Gluu
- using fully-hosted solutions like AWS Cognito and Auth0
We evaluated these solutions against a set of criteria that included:
- technical requirements
- storage mechanism for personal data
- community support
- ease of hosting (for self-hosted products)
- potential data migration out of the service
- our own team’s understanding
- operating costs
At the same time we talked to other departments and programmes who have experience with some of these approaches to learn more about their experiences. This gave us a broad understanding of the landscape which helped us make informed decisions as we built out the trial.
After we’d completed our analysis and engagement, we started our experimentation with Keycloak. During our discovery, we found that the Keycloak API did not support validating usernames and passwords. This meant we would need to build any frontend code that needed authorisation in Keycloak’s templating language.
This would introduce an additional support burden for technology that most GOV.UK developers would be unfamiliar with. It would also mean our frontend code would be split over several repositories and would not easily be able to make use of our usual design system and patterns.
We concluded that it would be quicker for us to use Ruby on Rails, and the Devise and Doorkeeper gems to write our own solution with a minimal feature set that would support our live experiment.
Hosting for the live experiment
For our initial experiment, we chose to host our service on the GOV.UK PaaS. The PaaS allowed us to quickly host applications and backing services so we could concentrate on developing our software.
We use a Concourse instance for our Continuous Integration and Delivery. We also record our technical decisions in Architectural Decision Records (ADRs) to create a written history and rationale for the project as it develops.
What’s next
Our technical team is now focusing their attention on iterating our software. We are ironing out bugs and making sure the service is robust, secure and reliable. We are refining our monitoring and alerting, and tidying up our technical documentation so that we can easily support the running service.
Looking further into the future, we want to add GOV.UK accounts to more services and as we do so, start to implement the next phases of our architecture. Alongside this, we’ll be making changes to our publishing architecture, moving from flat HTML to structured content, which we blogged about in November.
We’re going to keep blogging about our work as we learn, try and discover new things, so subscribe to read updates from this blog to stay up to date.
6 comments
Comment by Jeff posted on
Some great insights here. Really nice to see an exploration of large-scale architecture in the open, especially one that gives reasons as to the decisions made and not just a 'here is what we did'!
I'm interested to know why the decision was made to use Concourse for CI/ CD? Is it purely due to it's open source nature compared to the more known CI platforms, or is there more to it?
Comment by Bevan Loon posted on
Hello, thank you for your comment. We chose to use concourse for CI/CD because it met our needs and we already had experience within the team of using concourse for CI/CD for similar projects which helped with the pace of delivery.
Comment by Frankie Roberto posted on
Hi team,
One issue I'm interested in seeing your thinking on is how to resolve is the cross-domain problem. I suspect that many users will perceive all of http://www.gov.uk and all the services as "the same website" (as they're branded the same), but because the services are all on different subdomains, they can't share a session cookie, and so services will initially see a user as signed-out, even if they're signed-in elsewhere.
The default approach might be to have a sign in link which then redirects straight back to the same page but signed in, but is that confusing?
Similarly, if you sign out of a service, should it sign you out of just that service, or sign you out of everything?
Comment by Erin Raj-Staniland posted on
Hello, thanks for your comment. At the moment, we’re working on the account architecture for a single service so we’re still iterating our work here. As we look to expand the account functionality we will be blogging further about our thinking with this work - including what sign-out will look like. We’ll start by looking at the emerging OpenID Connect Front-Channel (https://openid.net/specs/openid-connect-frontchannel-1_0.html) and Back-Channel Logout (https://openid.net/specs/openid-connect-backchannel-1_0.html) standards for logging out multiple services.
Comment by Himal Mandalia posted on
I like the simple implementation relying on Devise and Doorkeeper to begin with, it's a well trod and well understood path that lets you do a surprising amount quickly.
I'm really interested in how this can drive a cross government federated data strategy. The attributes store is a good pattern, but when other government services start hooking into this there are going to be interesting conversations around sources of truth for personal data and existing stores across government. There could be an abstracted Attributes API which surface in its own store or pull from other sources. Many possibilities.
Comment by Himal Mandalia posted on
Last line should have read "There could be an abstracted Attributes API which surfaces from its own store or pulls from other sources."