In our strategy for growth, launched in June last year, we said that we wanted to explore whether emerging technologies can help users when interacting with GOV.UK.
The Government Digital Service (GDS) is running a series of experiments to explore, and test, how generative Artificial Intelligence (AI) could improve the user experience of GOV.UK. Chris Bellamy, Director of GOV.UK, has shared more about the work of the AI team, and how we’re approaching this technology — we suggest you read her blog post before this one to have that context.
Our approach to generative AI
OpenAI’s ChatGPT is an emerging technology. It’s only just over a year old, but it has generated a huge amount of interest and discussion. As Chris Bellamy writes: “We believe that there is potential for this technology to have a major, and positive, impact on how people use GOV.UK... [and] that the government has a duty to make sure it's used responsibly, and this duty is one that we do not take lightly.” This echoes the government's recommended approach described in a policy white paper last year.
This meant we took the approach of running a series of phased experiments in a controlled way to quickly gather data for analysis and evaluation of the system, and iteration. Our first experiment was using generative Large Language Models (the technology behind ChatGPT) to solve a problem that’s as old as GOV.UK itself — how we can save people time and make their interactions with government simpler, faster and easier.
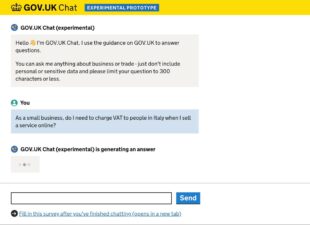
GOV.UK Chat
Our first experiment was an OpenAI powered chatbot, “grounded” on published information on the site (a method known as Retrieval Augmented Generation). We wanted to see if we could use this approach to enable users to find the information they need by asking questions of GOV.UK content in natural language - the way they would write or speak in everyday life.
We called the system we developed GOV.UK Chat. We took a phased approach to experimenting with GOV.UK Chat, where each phase would last a couple of weeks. At the end of each phase, we evaluated the data to determine our next step.
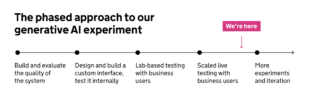
The first 3 phases were internal. This allowed us to develop the system safely prior to showing it to real users. This included a “red teaming” exercise, where colleagues from across government tried their hardest to break the system or make it not behave as intended.
We also evaluated the performance of the system at each stage, based on expert human assessment of the responses provided and the retrieved GOV.UK sources. Earlier on, this allowed us to identify an initial set of components which, together, produced the best results.
Following Phase 4 testing with a dozen users, with positive results, we scaled up testing by inviting 1,000 users to use GOV.UK Chat within a live private pilot — so we could continue to iterate and improve, and see how people would respond to the system. Collecting more data also helps us have more confidence in our evaluation of the technology.
Prior to each phase, especially Phase 5, we carefully considered what outcome or learning we wanted to achieve and designed the experiment and analysis accordingly.
We look forward to blogging about some of these areas in greater detail at a later date.
Protecting users’ privacy and security
As with all GDS’s work, we are committed to protecting users’ privacy and security. For this experiment, we put in safeguards to prevent users from submitting personal data in their query.
We also respect the personal data that exists on GOV.UK pages and worked closely with our data protection colleagues throughout the experiment in conducting a data protection impact assessment and mitigating any identified risks. For example, we removed GOV.UK pages with personal data from the system so they could not be sent to the LLM.
Our early findings
We conducted follow up surveys of users’ experience with GOV.UK Chat, as well as getting human experts to assess the accuracy and completeness of a sample of answers produced by the system.
Analysis of the survey data (n=157) revealed that most people liked using GOV.UK Chat to find the information they needed. Nearly 70% of users found the responses were useful and just under 65% of our users were satisfied with the experience.
From the testing we also gathered insights on how these results could be improved. For instance:
- sometimes a query could not be answered because the GOV.UK page was too long; we are working on a better strategy to chunk up the content without losing important context before it is passed to the LLM
- if questions could not be answered using content on GOV.UK, it’s clear we need to redirect people in different ways
Our results also highlighted known issues associated with the nascent nature of this technology. Overall, answers did not reach the highest level of accuracy demanded for a site like GOV.UK, where factual accuracy is crucial. We also observed a few cases of hallucination - where the system generated responses containing incorrect information presented as fact - mostly in response to users’ ambiguous or inappropriate queries.
Accuracy gains could be achieved by improving how we search for relevant GOV.UK information that we pass to the LLM, and by guiding users to phrase clear questions, as well as by exploring ways to generate answers that are better tailored to users’ circumstances.
We also found that some users underestimated or dismissed the inaccuracy risks with GOV.UK Chat, because of the credibility and duty of care associated with the GOV.UK brand. There were also some misunderstandings about how generative AI works. This could lead to users having misplaced confidence in a system that could be wrong some of the time. We’re working to make sure that users understand inaccuracy risks, and are able to access the reliable information from GOV.UK that they need.
What’s next
These findings validate why we’re taking a balanced, measured and data driven approach to this technology — we’re not moving fast and breaking things. We’re innovating and learning while maintaining GOV.UK’s reputation as a highly trusted (according to internal polling) information source and a ubiquitously recognised symbol in the UK.
Based on the positive outcomes and insights from this work, we’re rapidly iterating this experiment to address the issues of accuracy and reliability. In parallel we’re exploring other ways in which AI can help the millions of people who use GOV.UK every day.
Working across government
Teams across government are investigating how best to take advantage of this new technology, and the AI Safety Institute has been established to focus on advanced AI safety for the public interest. GDS is working closely with the Central Digital and Data Office (CDDO) and No.10 on the experiments. CDDO has today published the Generative AI Framework, which provides guidance across government departments.
We believe our GOV.UK Chat experiment can act as a “pathfinder” experiment for colleagues across government and the private sector, as to how to evaluate this technology safely.
If you’re interested in the work, please get in touch with the team via govuk-enquiries@digital.cabinet-office.gov.uk
Subscribe to Inside GOV.UK to keep up to date with our work.
27 comments
Comment by Jake Benilov posted on
Thanks for the write-up.
Out of interest, what LLM did you use to power the service?
Comment by Matthew Gregory posted on
Hi Jake,
Thanks for your comment. We used sentence-transformers/all-mpnet-base-v2 as the embedding model to create vector representations of both GOV.UK documents and user questions, aiding the retrieval process in our system. OpenAI’s gpt3.5-turbo-16k was used via API call for the answer generation element of the experiment.
Thanks,
Dr Matthew Gregory, Lead Data Scientist, GOV.UK
Comment by Victor Naroditskiy posted on
Hi Matthew,
We've been playing with RAG a lot at serenitygpt.com. A couple of things that may be useful:
- e5large-v2 worked way better than all-mpnet-base-v2 (here is our methodology for evaluating embedding models: https://serenitygpt.com/blog/how-to-choose-the-embedding-model-for-rag)
- gpt4 / gpt4-turbo worked way better than gpt3.5 especially in case of hallucinations (gpt-4 basically has none).
Thanks,
Victor
Comment by Wilson Silva posted on
"(...) sometimes a query could not be answered because the GOV.UK page was too long; we are working on a better strategy to chunk up the content without losing important context before it is passed to the LLM (...)"
"(...) OpenAI’s gpt3.5-turbo-16k was used via API call for the answer generation element of the experiment. (...)"
For larger pages, did you consider using gpt-4-turbo-preview, which has a context window 8 times larger than gpt3.5-turbo-16k? It is also a lot more intelligent. I wonder how much different the results would have been.
Comment by Matthew Gregory posted on
Hi Wilson, thankyou for your feedback.
We are currently iterating the tool, including testing different embedding and chat models.
We opted for this model as it suited the needs of our experiment, and gave us the opportunity to quickly begin investigating how an AI chatbot could improve the user experience of GOV.UK, leading to the initial findings detailed in our post. As I’m sure you are aware the landscape changes quickly, including model availability and cost.
Thanks,
Dr Matthew Gregory, Lead Data Scientist, GOV.UK
Comment by Terence Eden posted on
This sounds like a brilliant experiment. Obviously the training data is already open, but have you considered opening sourcing the training weights or final model?
Comment by Matthew Gregory posted on
Hi Terence,
Thank you for your kind words and interest in our GOV.UK Chat experiment!
Regarding your question about open-sourcing the training weights or the final model: The Large Language Model (LLM) we utilised for answer generation is developed and maintained by OpenAI. The model's training weights and underlying parameters are proprietary, meaning they are the intellectual property of OpenAI and are accessed by us through API calls.
While we can't open-source the LLM's parameters, we are exploring ways to contribute to the open-source community in other aspects of our project. This will include sharing our methodologies, best practices, or findings from the experiment in future blogs.
We appreciate your enthusiasm and hope this response helps clarify our position on open-sourcing aspects of the GOV.UK Chat experiment. If you have any further questions or ideas, we're all ears!
Best,
Dr Matthew Gregory, Lead Data Scientist, GOV.UK
Comment by Lisa Fast posted on
Fantastic! Other government teams from around the world are watching your leadership as usual. So glad you've done this.
I had thought avoiding hallucinations and chunking issues were fundamental to a RAG system. Did you use LangChain or something similar?
Would be wonderful if you could share more technical details.
Comment by Matthew Gregory posted on
Hi Lisa,
Thank you for your encouraging words and for following our work on the GOV.UK Chat experiment.
You've touched on some crucial technical aspects. Yes, we used LangChain to expedite our development process. For those unfamiliar, LangChain is a tool designed to facilitate the integration of language models like GPT into various applications, streamlining development.
Our initial chunking strategy was relatively straightforward, focusing on processing content at the page level. This approach, however, had its limitations, particularly in managing the maximum token limits imposed by the language model and ensuring accuracy.
Addressing your point about hallucinations - a known challenge with language models - our chunking method does play a role. By refining how we segment and process information, we aim to reduce the instances where the model might generate inaccurate or unrelated information. We're exploring more advanced chunking strategies to enhance the system's retrieval capabilities and overall accuracy. We are also considering how we might help our users ask clearer questions.
We're excited about sharing more technical details as we progress.
Thanks again for your support and interest.
Best regards,
Dr Matthew Gregory, Lead Data Scientist, GOV.UK
Comment by Michael G posted on
"We also found that some users underestimated or dismissed the inaccuracy risks with GOV.UK Chat, because of the credibility and duty of care associated with the GOV.UK brand. There were also some misunderstandings about how generative AI works. This could lead to users having misplaced confidence in a system that could be wrong some of the time. "
For the reason you stated above, I believe AI Chatbots shouldn't be used on gov.uk.
Comment by Pieter Goderis posted on
Dear sir,
I was triggered by your finding that “some users underestimated or dismissed the inaccuracy risks with GOV.UK Chat, because of the credibility and duty of care associated with the GOV.UK brand”.
This will indeed apply to government, banks and other well established brand names, where keeping trust in the brand is key.
What potential improvements do you see which could help better explain this to users?
Thanks,
Pieter Goderis
Comment by Matthew Gregory posted on
Hi Pieter, thanks for your question.
Trust in the information we provide is hugely important to us. We are exploring how we can guide users better in using tools powered by this kind of technology through user centred design approaches.
Best,
Dr Matthew Gregory, Lead Data Scientist, GOV.UK
Comment by Sourav Gaud posted on
Has this chatbot been trained on the whole of .gov website
Comment by Matthew Gregory posted on
Thanks Sourav, we did not train a model / chatbot in this experiment.
We used a technique called Retrieval Augmented Generation (RAG). This type of system works by “looking through” lots of information it has access to, in our case hundreds of thousands of GOV.UK pages. It “retrieves” the most relevant pages that can help answer the user’s question. Then, the system uses the retrieved pages as its context to "generate" an answer to the user’s question.
RAG is a state of the art approach for grounding a model on a bespoke knowledge base, especially one that changes daily like GOV.UK.
Best,
Dr Matthew Gregory, Lead Data Scientist, GOV.UK
Comment by Yulia posted on
In light of the ongoing debate regarding AI use, what privacy risks might users of this service face? Consequently, how does the GDS plan to prevent, detect, mitigate and defend against privacy risks or other harms?
Comment by Matthew Gregory posted on
Hi Yulia,
Thanks for getting in touch and for raising these important questions.
At GDS we are committed to protecting people's privacy and security. We thoroughly risk assessed the tool with our Data Protection Team.
Access to the tool was for invited users only, and test participants were instructed not to input personal data. We screen users’ queries for personal data and prevent that data from being stored or shared. We do not use GOV.UK pages that contain personal data in the tool.
Best regards,
Dr Matthew Gregory, Lead Data Scientist, GOV.UK
Comment by Mike Kujawski posted on
This is a great start! Thanks for sharing your findings so far and please continue to keep us all posted. I've been experimenting with building a free custom GPT that helps Canadians find and use federal government services using plain language. The data source is limited to public pages on Canada.ca.
I'm still testing various combinations of instructions to reduce the likelihood of hallucinations and direct people to specific official pages that will help them solve their problem.
If anyone has access to the GPT Store, they can try it out here: https://chat.openai.com/g/g-FQuHFwsV1-canadian-government-service-navigator
Once the GPT store is open to non-premium accounts, I hope to get more feedback. I think, eventually, Canada.ca will have an official AI chat agent essentially doing this function, but it's neat to see what's possible as this space evolves.
Comment by Kevin Xu posted on
Very interesting. How did you ensure that the LLM only uses content from GOV.UK, as opposed to other sources? And how did you implement changes when users tried to 'break' your system?
Was most of the work based around prompt generation or did you tune the model based on gov.uk data?
Comment by Matthew Gregory posted on
Hi Kevin, thanks for your interest and questions.
We did not train or fine-tune a model.
We used a technique called Retrieval Augmented Generation (RAG). This type of system works by “looking through” lots of information it has access to, in our case hundreds of thousands of GOV.UK pages. It “retrieves” the most relevant pages that can help answer the user’s question. Then, the system uses the retrieved pages as its context to “generate” an answer to the user’s question. We ensured the system relied mainly on the context and not knowledge in its weights through prompt engineering.
RAG is a state of the art approach for grounding a model on a bespoke knowledge base, especially one that changes daily like GOV.UK.
We found that the LLM we used for answer generation was quite robust against users intentionally trying to break the system. We had determined this before the experiment via a thorough “Red Teaming” exercise. Some exploits were observed which we created safeguards against.
Regards,
Dr Matthew Gregory, Lead Data Scientist, GOV.UK
Comment by Christian posted on
Great experiment. It would be interesting to know if you have also measured the user satisfaction using the old search or browsing method? Is that below 65% user satisfaction or higher?
Comment by Matthew Gregory posted on
Hey Christian, thanks for your kind words,
User satisfaction may provide a useful baseline measurement. However, we did not make a direct comparison as our metrics for search satisfaction are not suitable for this purpose.
Best regards,
Dr Matthew Gregory, Lead Data Scientist, GOV.UK
Comment by Ryan Hewitt posted on
Hi - interesting article. I'm curious to about the makeup of team who did the work.
What roles were involved (e.g. UR, content designer)? How is that different to other GDS projects?
Comment by Matthew Gregory posted on
Hi Ryan, thanks for your interest.
It was a multidisciplinary team, similar to lots of other teams at GDS. The roles included data scientists, product manager, delivery manager, software development (both front and back end), designers and user researchers.
Thanks,
Dr Matthew Gregory, Lead Data Scientist, GOV.UK
Comment by Kevin Thompson posted on
The chatbot is very basic, relying on the skill of the user to formulate questions, and yielding verbose flat text as a response. Why not introduce a further level of interaction, using dynamic forms to present information in a user engaging where, perhaps asking the user related questions to help them arrive at the final point? Could greater user of html headers be made to hold a description of page content in a form useful for the chatbot?
Comment by Matthew Gregory posted on
Hi Kevin, thanks for your comments and feedback.
This was an initial experiment to explore and test how generative AI can improve the user experience of GOV.UK. We are now focusing on iterating and improving the tool. This includes conducting more tests, for example with levels of interactivity, choice of embedding model and a better strategy to chunk up the content, as discussed in our post.
Regarding html headers, the system is already using html and metadata about pages.
Going forward, we hope to ensure the model is provided with relevant GOV.UK content and to increase the consistency of user-friendly, well-formatted answers.
Best,
Dr Matthew Gregory, Lead Data Scientist, GOV.UK
Comment by Sam Murray-Sutton posted on
Have you done any work to evaluate how this approach to finding info works compared to other methods, such as just using the search or browsing the site?
Comment by Matthew Gregory posted on
Hi Sam,
Thanks for your question.
We did not make a direct comparison to search or other navigation methods, as our existing metrics are not suitable for this purpose.
Best,
Dr Matthew Gregory, Lead Data Scientist, GOV.UK