What happened
On Friday 30 September the GOV.UK Team became aware that some users of GOV.UK were being prevented from accessing files hosted on GOV.UK. This was because some browsers were blocking the files with a message saying: “Deceptive site ahead”. The issue affected supplementary resources for government publications, such as PDF files.
As soon as we became aware of this problem we started our incident process. This coordinates investigation into the problem and communication across the organisation. We were able to establish that this identification of a deceptive site was incorrect and that it was related to a system misconfiguration. We resolved this misconfiguration within 2 hours of declaring the incident, which allowed users to access files again.
What users saw
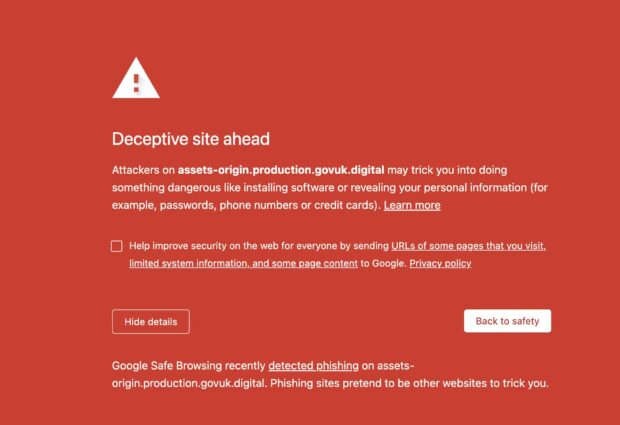
Users could browse www.gov.uk as normal, but if they followed certain links, they would see a “Deceptive site ahead” warning in their browser. This type of warning occurs when web browsers block access to a website that may be pretending to be another website. The purpose of a deceptive website is typically malicious, potentially acting as a phishing scam or tricking users into downloading software intended to harm their computers (such as malware or ransomware).
A lot of pages on GOV.UK contain lists of supporting documents, which can be in a variety of different file formats. Taking the Household Support Fund: guidance for local councils guidance, for example, we can see attachment types including HTML, PDF and MS Excel Spreadsheet.

Users attempting to view an attachment that renders in their browser, such as a PDF, would see the browser security warning. They could still download the file by right-clicking the link and saving it.
The warning displayed the domain name of the site that was blocked: "assets-origin.production.govuk.digital". This is an internal domain that GOV.UK uses and is not available to the public. It seemed odd that we were only seeing the warning when trying to view certain file types, and that the files could still be downloaded using the right-click workaround.
Cause of the problem
There were 2 factors that contributed to the cause of this incident. These were:
- an internal GOV.UK domain name being added to a list of unsafe sites that web browsers use
- a misconfiguration that led to an internal domain name being used in the process to deliver file downloads on GOV.UK.
Unsafe site list
Most major web browsers make use of the Safe Browsing API provided by Google. This tool provides a list of websites that have been detected as serving deceiving or malicious content. Web browsers then block access when a user attempts to view these sites.
As a government website, we highly value this Safe Browsing API tool as it helps keep users safe. Websites attempting to deceive users by appearing to be a government website are unfortunately common and provide numerous risks to users.
We understand that this Safe Browsing API tool became aware of an internal domain we were testing on the public internet. As the software we were testing looks similar to GOV.UK, as a pre-release version, it was added to the list. The site was hosted on a subdomain of “govuk.digital”, however we found that it wasn’t just that site that was flagged as potentially deceptive. Instead, the whole “govuk.digital” domain was flagged. This meant this problem affected not just the site being tested, but any of our other internal tools that use the “govuk.digital” domain.
Earlier Misconfiguration
It was a surprise to us that having the “govuk.digital” domain marked as deceptive was impacting members of the public. It was only for internal usage and there should not be any internal tooling exposed when files are served to users.
We discovered that some configuration changes a few weeks earlier had caused a modest problem that had gone undetected, which then became a severe problem once our internal domain was marked as deceptive.
When users view PDFs or images from GOV.UK in their browser, they are also served a small icon called a favicon, which is displayed in the browser tab and bookmarks. Browsers automatically request it when viewing a file on a site. The earlier configuration changes had caused a request for this icon to be redirected to an internal domain name, “assets-origin.production.govuk.digital”. This domain name is not served on the public internet, which meant requests for this icon failed outside our internal network.
The consequence of this problem is very modest for users: it doesn’t affect viewing the requested file, it just means that the icon in the browser didn’t show. Our monitoring had not captured this problem, so this issue lay undiscovered following the configuration change.
Once the internal domain was marked as deceptive, this modest problem became significant. When users requested a PDF in their web browser, their browser would also attempt to request the icon from the blocked domain. The browser would then automatically block all other requests so that the user would not be served the PDF or image they requested.
How we fixed it
Once we’d identified the code change that introduced the issue, we reached out to the team that authored the change, to check that undoing it wouldn’t cause additional issues. We then checked on a test environment to make sure that reverting the change would fix the issue as expected. Finally, we applied the revert to our production environment.
This resolved the issue for our users, who could now access all attachments as normal. However, we still had some internal tooling that relied on the govuk.digital domain, which was still being blocked by the browser.
We followed Google’s well-documented process to request a review of our domain. Within 24 hours, the domain was successfully removed from the Safe Browsing block list, meaning we now had full access to our tooling.
Next steps
This incident provided us with a reminder of the importance that GOV.UK can be trusted. As people working on GOV.UK, we place a lot of pride in the trust people have in GOV.UK and we work hard to maintain and develop it. This incident also reminded us that trust is not just held by users but also by the systems that operate the infrastructure of the internet and that we risk their trust by taking actions they find surprising.
In our incident review, we questioned the steps that could be taken to avoid a recurrence of an incident like this.
We've now iterated the request headers we set at the CDN layer, to be stricter in terms of the headers we trust at the application level. We've also reviewed our policy and guidelines around usage of internal domain names, setting clearer guidance for teams. Finally, we will improve our monitoring capabilities to catch issues of this nature should they occur again in future.
Subscribe to Inside GOV.UK to keep up to date with our work
Interested in this work? Come work at GDS