
What happened
On Tuesday 8 June 2021 the primary content delivery network (CDN) that GOV.UK uses had an outage which caused a major disruption of services on the site and other non-governmental sites across the world. For less than an hour users visiting GOV.UK were unable to access information and services and saw error pages instead.
The incident was detected 4 minutes after it began. An incident lead was agreed, and together with our communications lead began our formal incident process.
With incidents like this, it's important we stay calm and act with purpose. After investigation the incident team confirmed that the issue was caused by the CDN and identified GOV.UK's documented process for failing over to the secondary CDN. The incident lead agreed with the head of technology and architecture to monitor the situation with the primary CDN for 15 minutes before starting the failover process. This involved switching over to our secondary CDN to ensure users could access information on GOV.UK.
What users saw
Visitors to GOV.UK (and the other affected sites) saw error pages with an “Error 503 Service Unavailable” heading.
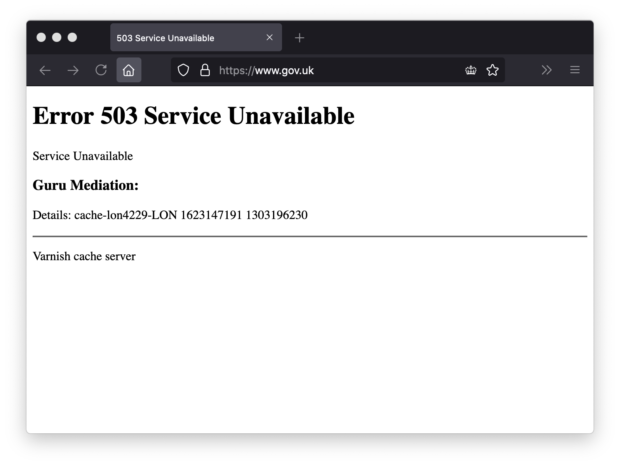
Unfortunately, this error page was outside our control. It was not informative and fell well short of our usual standards of content design.
Cause of the problem
This incident was caused by an issue with the primary CDN we use. Many websites were affected, because they all use the same CDN.
A CDN is a network of computers in data centers all over the country and all around the world. These computers are optimised to be very good at serving web pages. Particularly ones that serve the same pages to lots of different people — like GOV.UK.
When millions of people request the same page, instead of a web server handling each request separately the CDN can "cache" the server's response once and serve that to everyone.
Roughly 93% of requests to GOV.UK are served from the CDN's cache. Because the CDN is so heavily optimised for this use case, it's much more efficient to serve pages from the cache. A good cache hit rate means that GOV.UK costs less to run, and emits less carbon dioxide.
Effective use of a CDN means that pages load more quickly, especially on mobile devices with spotty internet connections. Because a CDN is geographically distributed, users fetch pages from a datacenter near them, instead of a central datacenter further away.
CDNs usually provide very high levels of reliability. GOV.UK's CDN is configured to serve static fallback pages (called "mirrors") if anything goes wrong behind the scenes with our main infrastructure.
However, on very rare occasions things break. No infrastructure is 100% reliable. Because CDNs have to sit at the "edge" of the network, when they break the whole website goes down. So it's important to have a backup plan.
Our plan for an incident like this
We know that the CDN is a potential single point of failure, so we have a plan for this situation.
We have a secondary CDN which is always on, but it doesn't usually serve any traffic. We refer to switching from the primary CDN to the secondary as "fail over".
Because the secondary CDN represents degraded service where dynamic parts of GOV.UK, like search or location based services, don't function in their usual high quality way, it's a big decision to fail over. If the incident with the primary CDN is resolved quickly (which they often are), then failing over too soon could make the incident on GOV.UK worse.
So the plan was to wait 15 minutes to establish the severity of the issue with the primary CDN, and then fail over if the issues persisted.
Usually, traffic goes to our primary CDN because of our domain name system (DNS) records. DNS is how your computer works out the internet protocol (IP) address of the computer to connect to when you ask it to go to www.gov.uk.
We had prepared for this scenario, and had the code to update our DNS records ready to run.
Resolving the incident
15 minutes after detecting the incident, with no change in the status of the issue we made the decision to fail over to the secondary CDN.
For technical reasons, changes to DNS records can take a long time. Within 30 minutes the incident team had deployed the changes needed, and traffic was beginning to be routed to the secondary CDN.
When we deployed, we could see that the issues with our primary CDN appeared to be being resolved. After monitoring the improvements for a few minutes, we made the decision to switch back. When functioning, the primary CDN provides a better service than the secondary ‘fallback’.
We continued to monitor the situation for an hour, and once we were confident that there were no remaining issues, we declared the incident as resolved.
Next steps
As with all our incidents we follow up with a formal incident review where we can discuss what happened, how well we responded, and what actions we need to take to make sure we do better next time. In particular, we'll consider how we can improve the speed and transparency of communications, and how planned changes to our platform technology and processes can allow us to recover from future incidents more quickly.
Subscribe to Inside GOV.UK to keep up to date with our work.
Read more about our plans to recruit more technologists and look at GDS’s career page for more information and open roles.
4 comments
Comment by Mark Williams posted on
very informative, thank you
Comment by Paul C posted on
This is very reassuring, thank you.
Comment by Huw posted on
Interesting and clear explanation of what happened and what you did
Well done
Comment by Tracy posted on
Great update on the incident using plain language