GOV.UK hosts over 400,000 pieces of content from a multitude of organisations. As well as 45 ministerial and non-ministerial departments, there are hundreds of agencies and public bodies, and dozens of high-profile groups, public information groups, and devolved administrations. Having all this in one place lets users interact with the government without having to know how the government works.
It also means that GOV.UK content can cover anything from helping a user complete a task, like getting a passport, to providing business users with consultations, like Call for evidence: the operation of Insurance Premium Tax.
We know the vast majority of users come to GOV.UK directly from an external search engine. So it's really important that we help users move on from the information they have landed on easily, and, if appropriate, by providing the right navigational aids.
We’ve already produced step by step navigation to guide users through complex service journeys, and introduced a site-wide taxonomy to categorise all content into topics. This means users can find information about the topic they care about without having to know how the government is structured.
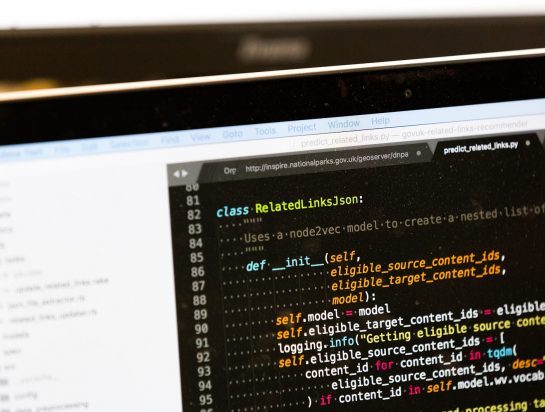
But over the last 6 months, we’ve also tested and released a machine learning algorithm that can generate links of related content.
Machine learning provides computers with the ability to learn without being explicitly programmed. Machine learning algorithms can be trained to perform and automate tasks that have previously been thought of as tasks that only humans can do.
‘Mainstream’ versus ‘Whitehall’
GOV.UK content falls into one of 2 buckets – ‘mainstream’ and ‘Whitehall’.
Mainstream is made up of around 2,000 pieces of high traffic content (57% of all page views until June 2019), like services that a user can complete. This content is managed by a dedicated team at GDS, and totals about 2% of all GOV.UK content. It includes curated related links that have been suggested by people who know the service areas well.
The remaining 98% of GOV.UK content is Whitehall, the vast majority of which didn’t have any related links. It would be difficult for content designers to go through all Whitehall content and suggest related links – their time is better spent making sure the content is well written and user-focused.
We didn’t know if an algorithm would be able to compete with humans with years of experience and understanding of government content. But by measuring the performance of a number of predictive algorithms, we were able to determine if an automated process for adding related links could help our users get the information they need more quickly.
Testing algorithms
We A/B tested 3 algorithms across all our GOV.UK content. Our metrics to determine success were:
- an increase in clicks on related links
- a decrease in clicks on navigational elements, like the header, footer, search box and breadcrumbs – these are often signs that a user is lost or restarting their journey
Throughout the process of testing and getting feedback from publishers, we began to see more potential for using an algorithm to create related links. For example:
- news items only ever suggest other news articles
- no other document type displays news as related links
- we don’t display related links on fatality notices
This would allow us to minimise the risk of an algorithm displaying a piece of content that might be insensitive or potentially unrelated.
The algorithm goes live
Once we’d chosen our preferred algorithm, we spent the following quarter working to get it into production.
This involved running all our content through the algorithm and training it using 3 weeks’ worth of user journey data. As some content on GOV.UK is less popular than others, 3 weeks gave us a well-rounded view of user journeys across all our content.
By repeating this process, we’re able to release a new version of the algorithm every 3 weeks.
With many weeks and much hard work from the team, on 3 July 2019, we added related links to over 400,000 pieces of content on GOV.UK.
What happens next
Using the algorithm, we’ll add further related links to Whitehall content, and take some time to monitor performance.
We’ll continue to use the same metrics, but we’ll also check them against journey-level metrics so we can better understand user behaviour and the usefulness of the automated related links. We also expect that we will have to tweak the accuracy threshold as we get more feedback from publishers.
This is the first time that GDS has tested, built and released a machine learning pipeline, and there’s a lot of learning to be shared with the rest of the organisation and wider government. The broader implications for helping to deliver smarter, more efficient public services are substantial.
We have also been able to test new technologies that have been recently introduced to the GOV.UK tech stack like Concourse and Terraform.
This piece of work has helped us to embed data scientists into multi-disciplinary teams and encouraged us to look at tackling larger problems that data science could help with.
If you want to talk to us about this work or have any interesting projects you would like to share with this, please leave a comment.
You can follow Ganesh on Twitter.
2 comments
Comment by Travis posted on
Thanks for the post, it's really interesting - but how does one even begin to start working with machine learning?!
I'm working with a large charity, but am totally lost with machine learning at this point.
Are you able to set out a couple of the very first steps an organisation would need to take to start doing something like this?
Comment by Ganesh Senthi posted on
Hi Travis, thanks for the comment. More than happy to help. Do you want to send me a DM on twitter? Thanks Ganesh